数据库视图
数据库中的视图是一个虚拟的表,它是由一个或多个表的数据经过特定的查询语句组成的。视图的作用如下:
- 简化复杂查询:视图可以将多个表的数据组合起来,使得复杂的查询可以被简化。使用视图可以将多个SELECT语句组合在一起,从而减少代码量和提高代码可读性。
- 数据安全性:视图可以对数据库的敏感数据进行保护。通过限制用户对表的访问权限,只能通过视图查询敏感数据,可以避免敏感数据被恶意篡改和删除。
- 简化数据访问:视图可以隐藏数据表的细节,只暴露必要的数据给用户。这样用户只需关注他们需要的数据,而不用关心数据表的具体实现。
- 可以向应用程序提供标准视图:应用程序可以通过访问视图而不是表来获取数据,这可以使应用程序更加灵活。当数据表结构发生变化时,只需要更改视图而不是应用程序代码。
- 提高性能:视图可以提高查询性能,因为它可以缓存一些常用的查询结果。当多个用户需要相同的查询结果时,视图可以避免重复查询。
- 数据一致性:视图可以保证数据的一致性,因为它可以对多个表的数据进行联合查询。当修改一个视图时,它会自动更新涉及到的所有数据表,从而保证数据的一致性。
总的来说,视图是一种非常有用的数据库对象,可以提高查询性能、保护敏感数据、简化数据访问等。但是需要注意的是,视图可能会占用额外的存储空间和计算资源。
开发数据库应用
不要把数据库当“黑盒”,每个数据库都是非常不同的,必须深入了解你所使用的数据库的体系结构和特征
- 不同数据库实现的锁和并发控制机制不同
- Oracle 实现的锁机制
- 只有修改才加行级锁
- Read 绝对不会对数据加锁
- Writer 不会阻塞 Reader
- 读写器绝对不会阻塞写入器
- Oracle 实现的锁机制
- 不同的数据库对于 Null 值的实现不同
- 认为 Null 是未知值,与其他任何值都不相等,使用 IS NULL / IS NOT NULL 来进行判断
- 认为 Null 是合法值,用来表示缺失或未知的数据,在使用比较运算符时,一个操作数为 Null 则结果为 false
- 认为 Null 是合法值,用来表示缺失或未知的数据,在使用比较运算符时,一个操作数为 Null 则结果为 Null
- …….
1
select avg(coalesce(t.x, 0)) from t;
性能、安全性都是适当的被设计出来的
索引结构
更适合磁盘实现的树必须具备以下属性:
高扇出,以改善临近键的数据局限性
低高度,以减少遍历期间的寻道次数
B 树(B+树)
- B 树(B+树)结构
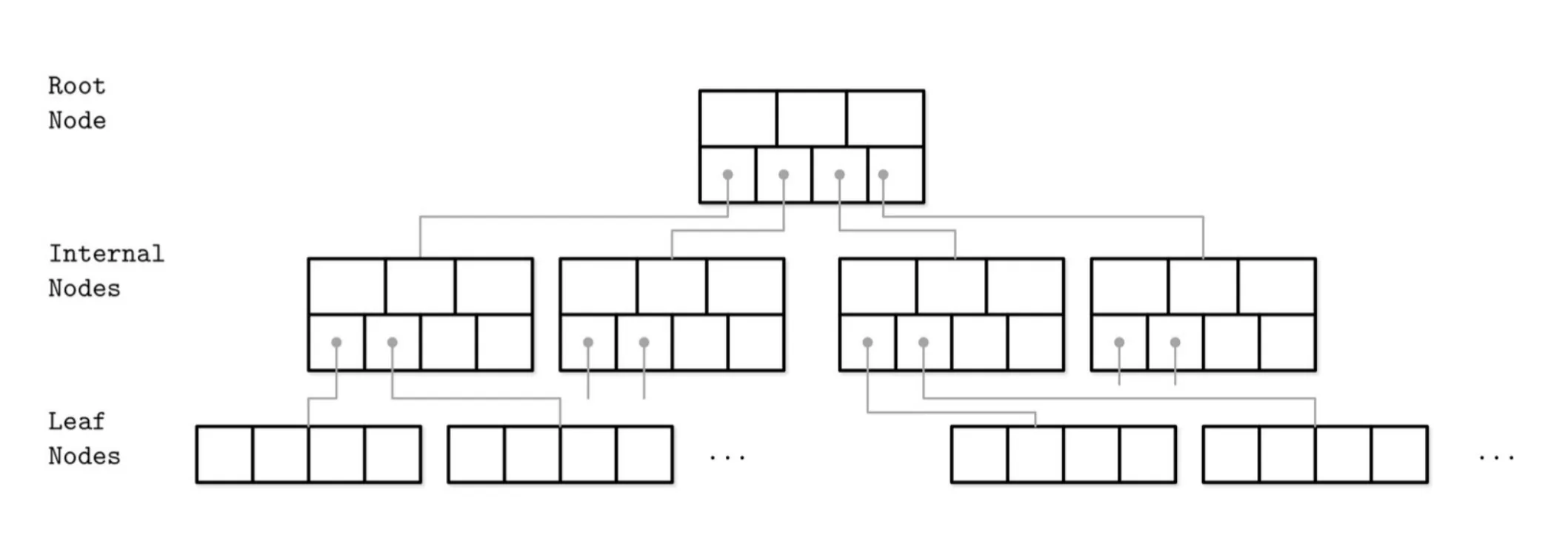
最小度数 t,除根结点外每个内部结点至少有 t-1 个关键字,至多可包含 2t-1 个关键字
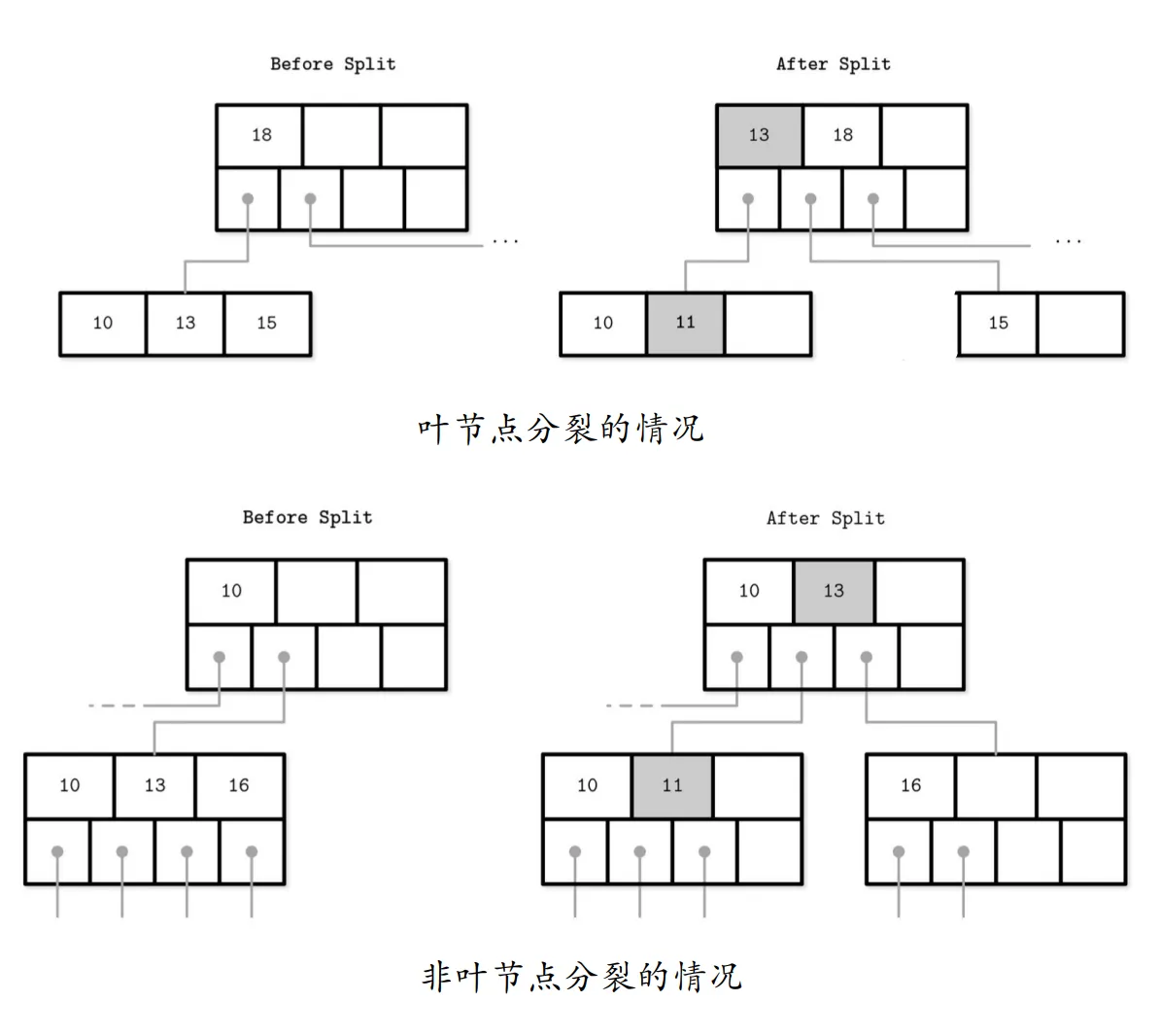
B 树的分裂操作(插入新结点时发现叶结点个数已满):
- 将包含 2t-1 个元素的满结点,从中间分裂成两个包含 t-1 个关键字的子结点
- 将中间关键字提升到父结点,标识两棵新树的划分点
- 如果此操作导致父结点也成为满结点,则递归地进行分裂操作
B 树的查找算法
- 查找,从根节点到叶节点的单向遍历
- 从根节点上执行⼆分搜索算法,将要搜索的 $K$ ,与存储在根节点中的 $K_{n}$ 进行比较,直到找到大于 $K$ 的第⼀个分隔键,这样定位了⼀个要搜索的子树,顺着相应指针继续相同的搜索过程,直到目标叶节点,找到数据主文件指针
B 树(B+树)逻辑存储结构
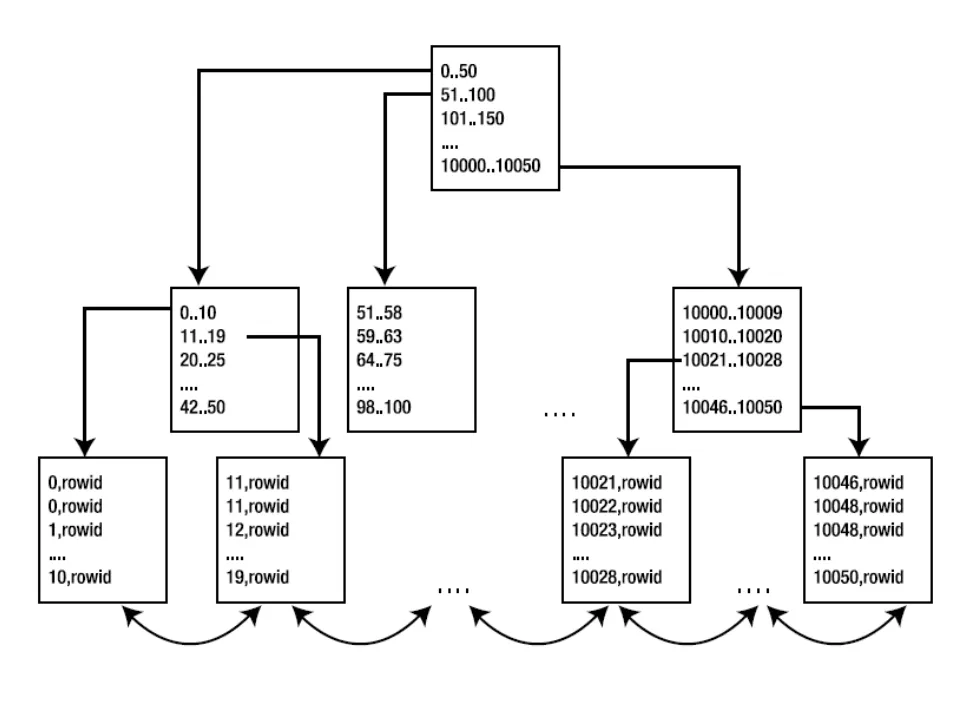
索引对数据的访问
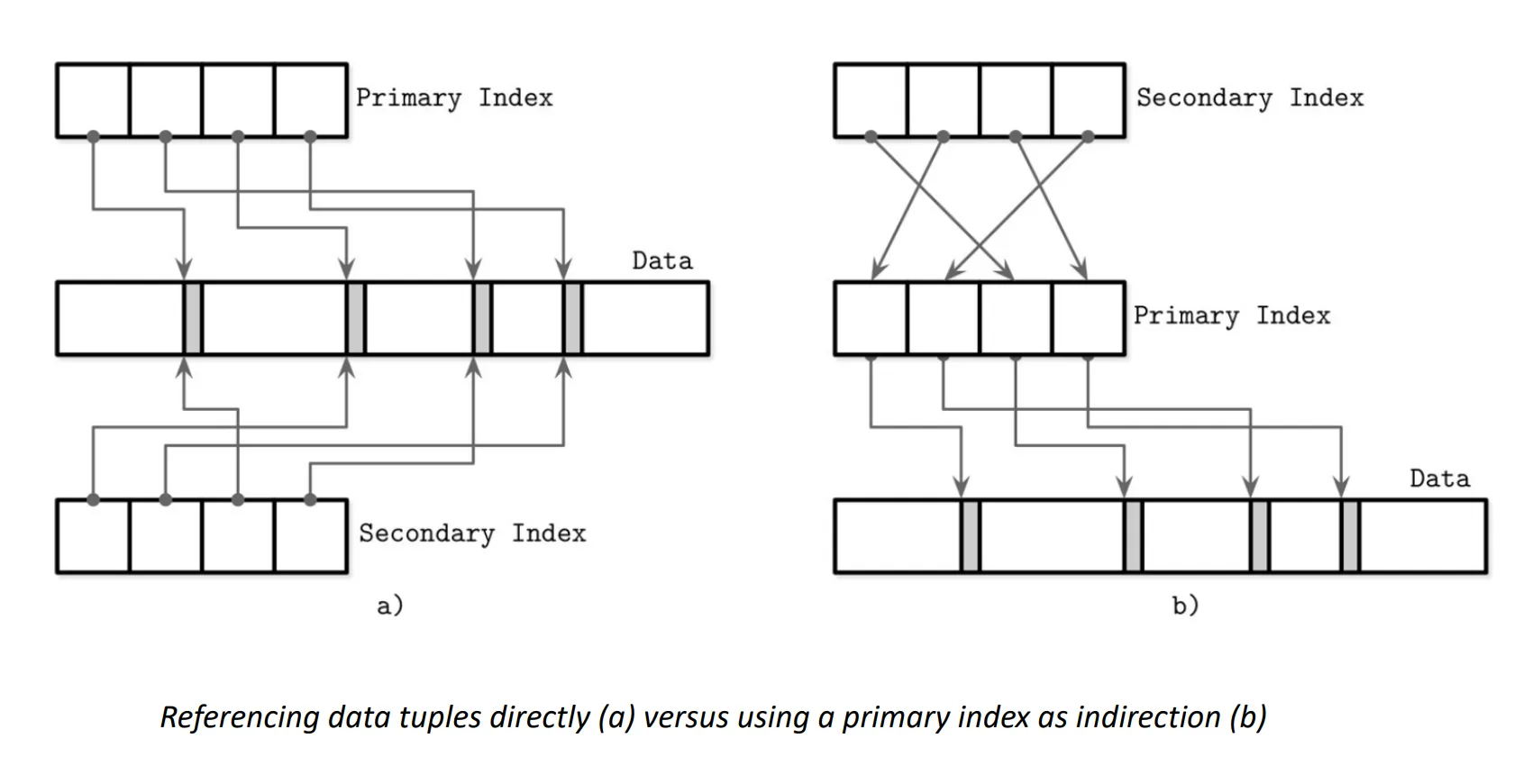
- 通过主键索引访问基本表:先访问索引,得到文件的偏移量,再以此来访问基本表
- 通过二级索引访问基本表:
- 二级索引直接指向基本表(读数据时只需要访问一次索引,写数据时需要访问两次索引)
- 二级索引指向主键索引(读数据时只需要访问两次索引,写数据时需要访问一次索引)
- 复合键索引,本质上是按照排名第⼀的字段进行索引(查询的字段全在复合索引中则可不使用基本表)
数据表的物理实现
在数据库物理实现中,一个数据页(page)通常被划分为若干个固定大小的数据块(block),每个数据块包含一个或多个数据项(record),而这些数据项的大小并不固定
为了能够高效地管理这些数据项,数据库系统采用了一种称为 slotted page 的技术
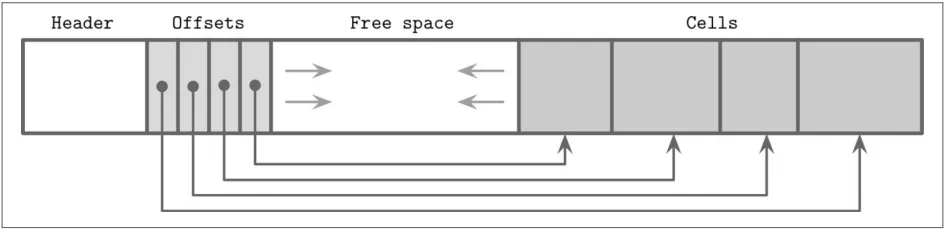
其中,Header 中包含的数据一般有:
- Page 类型:该 page 的类型,如数据页、索引页、系统页等
- Page 编号:该 page 在数据库文件中的唯一标识符
- 空闲空间:该 page 中还剩余的可用空间大小
- 版本号:用于记录该 page 的版本信息,主要用于并发控制
- 标记位:用于标记该 page 的状态,如是否被锁定、是否被修改等
- Checksum:用于校验该 page 的数据完整性,防止数据损坏或篡改
- ……
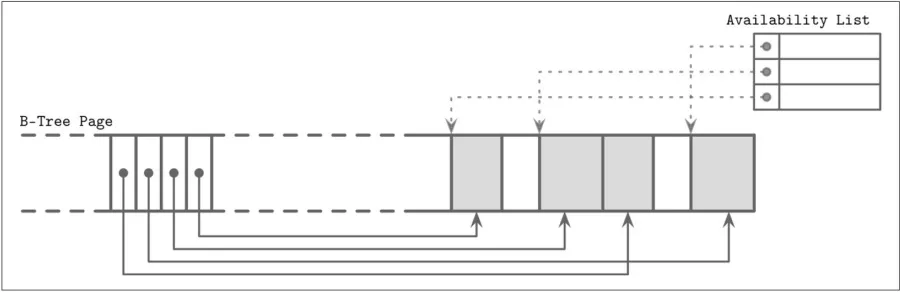
为了能够回收已删除记录的空间,构建指针链表 Freeblock,并指向第⼀个空闲块的指针保存在页头部,保存可用字节数(确定是否能在碎片整理后被放入该页)
- 使用空闲块的策略:
- 首次适配优先(找第⼀个适配的空闲块,会带来额外开销)
- 最佳适配优先(找⼀个剩余段最小的空间)
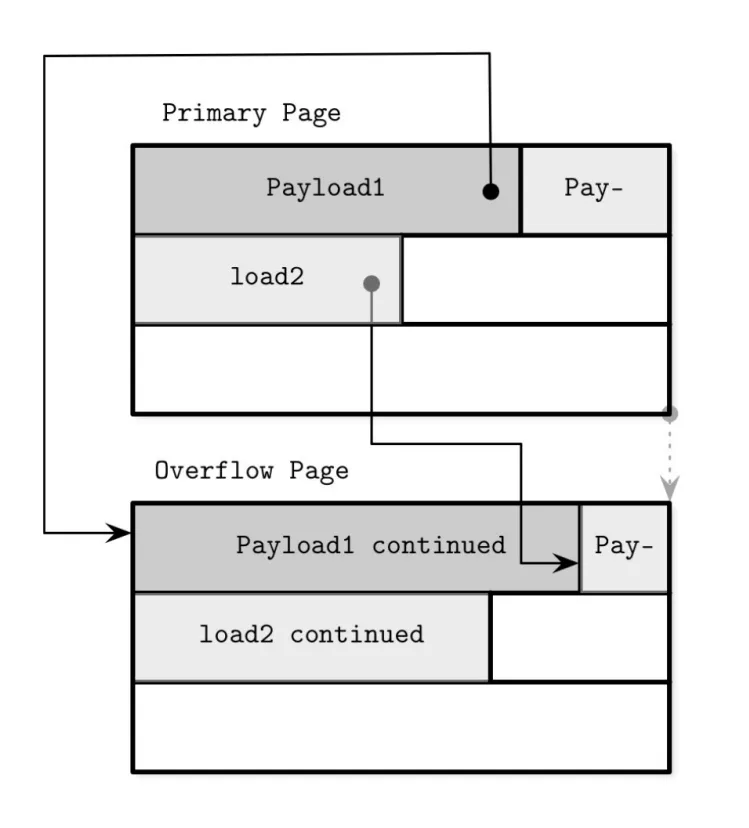
行迁移:页溢出时,在原页面中留出一个指针大小的空间,然后将该记录的剩余部分存储在新的页面中
额外的小问题:
- 经验规律 70% / 30% 原则,留下一定的空间,最大程度上避免行迁移的产生
- 校验和:checksum / XOR,循环冗余校验 CRC(检测连续比特位的损坏)
SQL 语法技巧
聚合计算时处理 null
使用 COALESCE 函数:coalesce(expr_1, expr_2, …, expr_n),遇到非 null 值即停止判断并返回该值
1
select avg(coalesce(t.x, 0)) from t;
删除字符串中部分内容
使用 REPLACE 函数:replace(original-string,search-string,replace-string)
- original-string: 被搜索的字符串
- search-string: 要搜索并被 replace-string 替换的字符串(若为空串,则返回原始字符串)
- replace-string: 该字符串用于替换 search-string(若为空串,则删除出现的所有 search-string)
1
update `article` set title=replace(title, 'w3cschool', 'hello');
计算中位数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15-- Oracle
select median(sal) from emp where deptno=20;
-- MySQL/PostgreSQL
select avg(sal)
from (
select e.sal
from emp e, emp d
where e.deptno=d.deptno
and e.deptno=20
group by e.sal
having
sum(case when e.sal=d.sal then 1 else 0 end)
>= abs(sum(sign(e.sal-d.sal)))
) t;
数据库模式设计之层次结构
树状结构
只要对象的类型相同,而对象的层树可变,其关系就应该被建模为树结构
数据库模式设计中的三种树模型
Adjacency Model:邻接模型
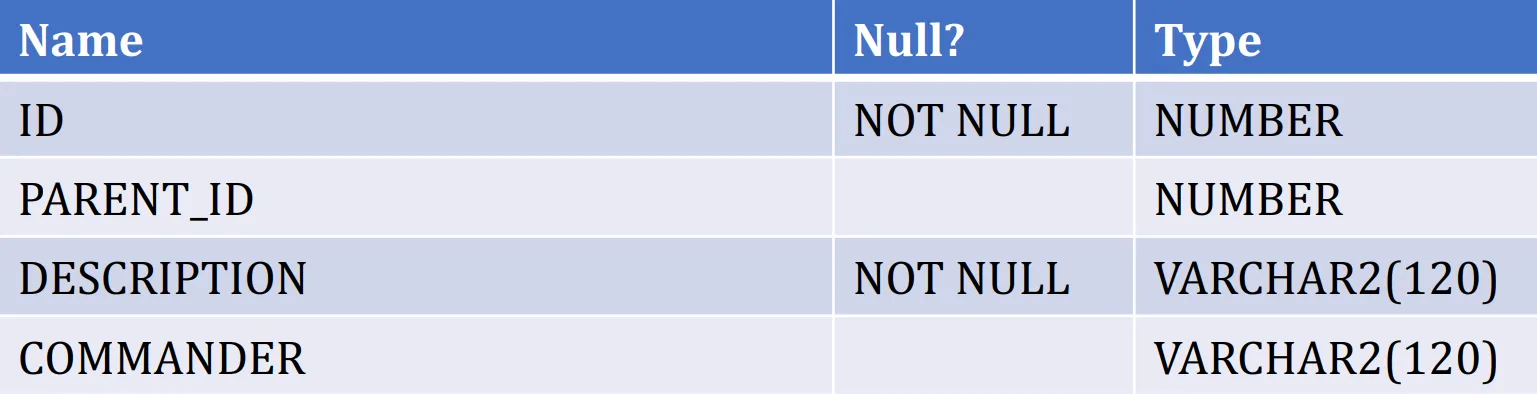
Materialized Path Model:物化路径模型
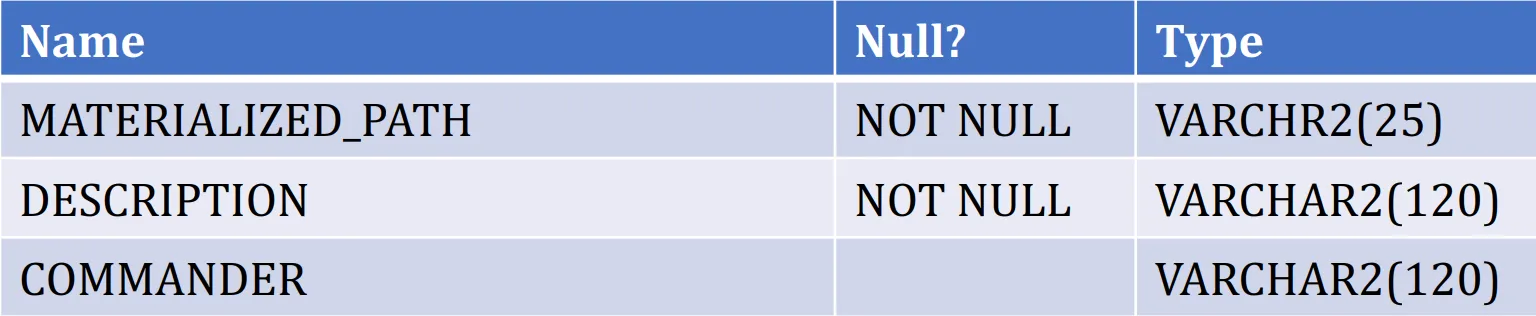
Nested Set Model:嵌套集合模型