项目背景
关于开源项目 SentiStrength
SentiStrength为 Mike Thelwall 等人根据 MySpace 网站数据开发的社交文本情感分析工具官网提供了该工具的原版 jar 包,各种使用手册,以及可以试运行的 demo 等
除此之外,它还罗列了与该工具有关的若干论文,并提供了工具开发过程中标注的数据集
官网 jar 包的反编译结果以发布于:https://github.com/skx980810/SentiStrength
- 关于软工文本情感分析
软件工程文本的情感分析已广泛应用于软件工程研究,例如评估应用程序评论或分析开发人员在提交信息中的情感。但是,为分析社交媒体文本或产品评论而开发的情感分析工具在软件工程数据集上效果不佳。
研究发现开发人员在各种软件工程活动中表达了情感,因此需要一种针对软件工程领域的定制情感分析工具。
为了更好地支持在软件工程任务中使用自动情感分析,研究人员使用了多种技术手段,如建立软件工程领域指定的情感字典、使用经过标注的软件工程领域文本来训练机器学习模型,以进一步提高结果的准确性。
- 关于大模型时代的机器学习
随着硬件计算能力的提高、数据的积累和模型结构的进步,我们开始能够训练出更大、更复杂的模型,前言的机器学习进入真正意义上的 “大模型时代”。
更强的表达能力:更多的参数意味着更好地拟合复杂的数据分布 能力,理论上能够表示更丰富的函数空间
更好的泛化能力:虽然存在过拟合的可能,但在大数据背景下,大模型往往能够实现更好的泛化
转移学习能力强:可以被用作预训练模型,对其他相关任务进行微调,大大减少了从头训练模型的需要、
对于下游的科研任务,大模型可以带来研究方法的变革。例如,传统上,机器学习研究重视特征工程和模型的选择;而在大模型时代,端到端的训练、预训练-微调的范式、自监督学习等方法逐渐占据主导地位。
核心内容
- 数据集构建
- 助教提供了两个已构建的软工文本数据集
sof-4423和app-review - 通过爬虫从以相关网站获取软工文本数据,人工标注并对结果进行过滤,新构建了 1000 条数据的数据集
- 使用多线程加速,提高爬虫效率:
ThreadPoolExecutor - 使用爬虫代理 IP 池规避 API 限流:https://github.com/jhao104/proxy_pool
- 使用多线程加速,提高爬虫效率:
- 助教提供了两个已构建的软工文本数据集



预处理规则构建
- 参考论文 SentiCR 中的预处理方式:https://github.com/senticr/SentiCR

- 额外引入新的词性分析及相关处理
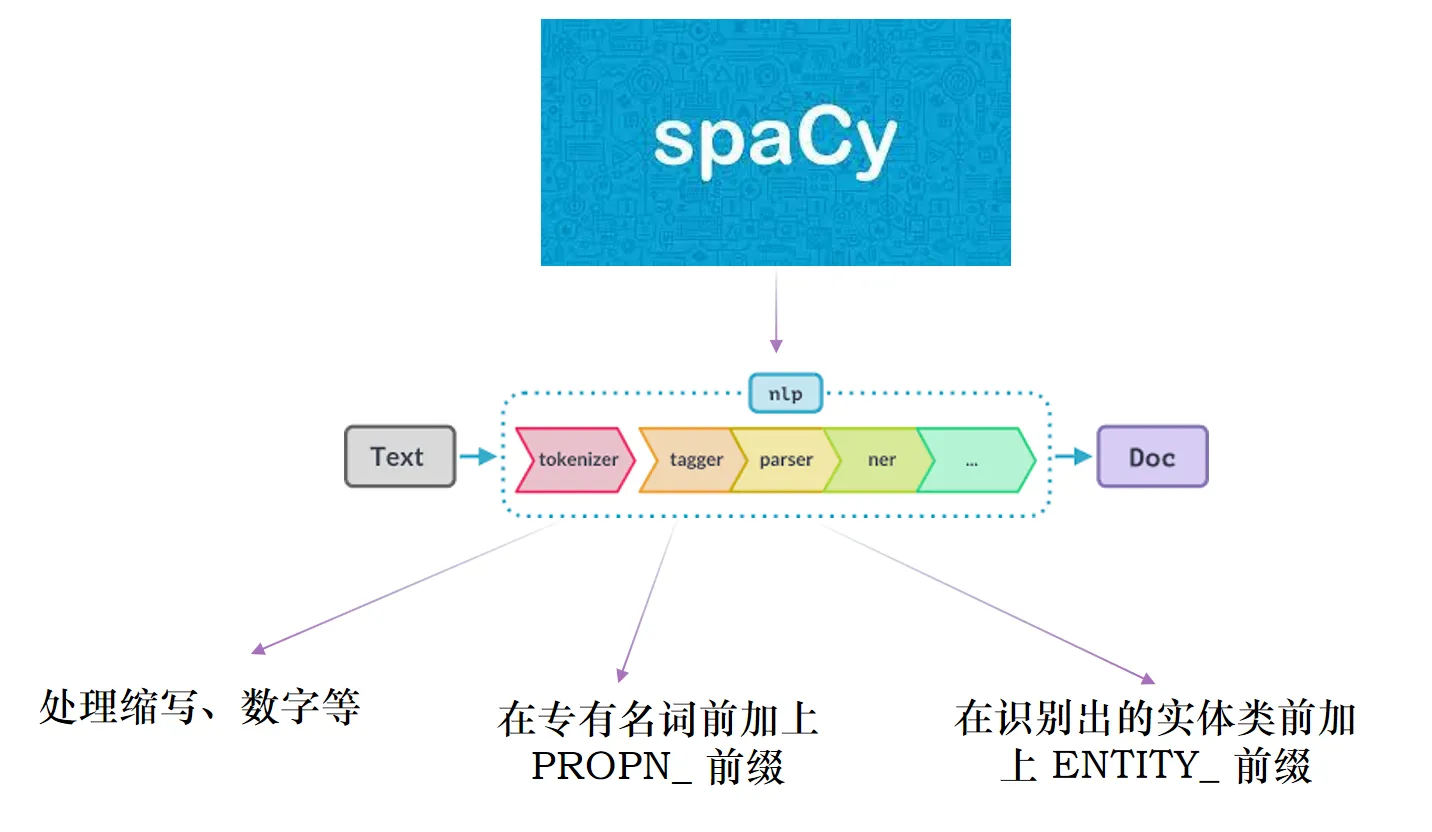
- 额外处理斜体、全大写和一些软件工程领域特定词汇
模型训练与微调
将数据集分为训练集和测试集,训练集用于模型训练/微调,测试集用于评估模型预测准确性
分别采用传统的训练小型机器学习模型和微调大模型的方式来进行实践
使用 Python中的机器学习库 scikit-learn 来构建并训练各种不同的机器学习模型
使用 OpenAI 开放可通过 API 进行在线微调的模型来做微调
- Ada:中小型语言模型,2 亿参数,可用于自然语言生成、回答问题和文本分类等任务
- Babbage:中型语言模型,6 亿参数,可用于自然语言生成、回答问题和文本分类等任务
- Curie:中大型语言模型,13 亿参数,可用于自然语言生成、回答问题和文本分类等任务
- Davinci:大型的语言模型,175 亿参数,目前最先进、最强大的语言模型之一,能够执行多种自然语言任务,如问答、生成、摘要等
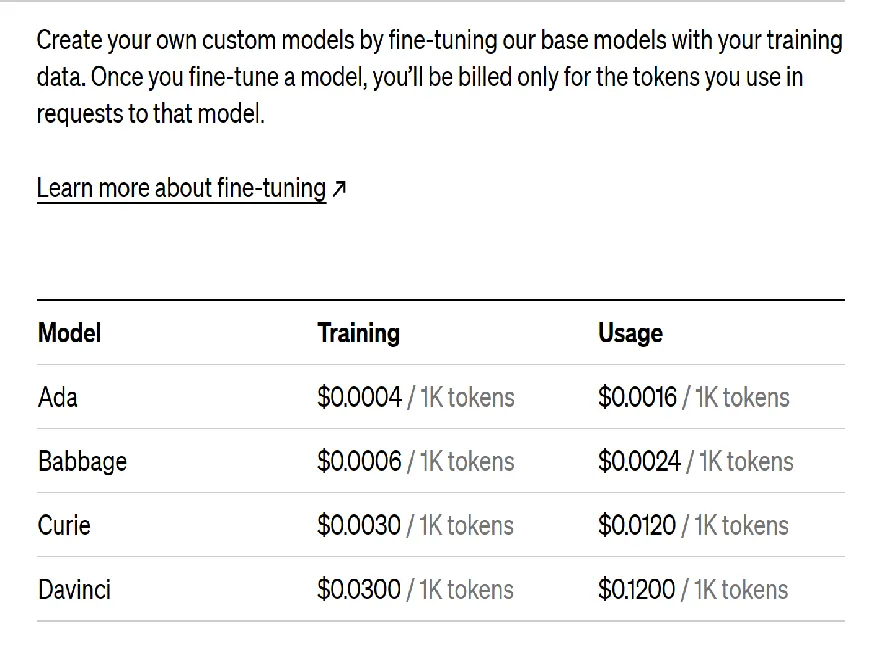
OpenAI 目前可能已经关闭对以上模型的微调支持,最新可微调的模型信息详见 OpenAI 官网文档:https://platform.openai.com/docs/guides/fine-tuning
实验与总结
实验概述
- 训练一个三分类器对软工文本进行情感预测(1 positive,0 neutral,-1 negative)
- 训练数据集以助教提供的预划分的
sof4423为基准,自行构建的数据集作为辅助进行对比实验
处理流程
以 SentiCR 为参考:https://github.com/senticr/SentiCR
- 对文本数据进行预处理(使用 NLP 算法,进行展开缩写、去除 URL 等预处理)
- 将预处理后的文本数据转换成向量(使用 TF-IDF 算法将文本转化为向量)
- 使用训练集训练一个三分类器(使用 sikit-learn 库中不同的分类器进行训练和测试)
- 将训练好的模型在测试集上进行测试
改进思路
- 方向一:预处理,尝试不同的文本预处理方法
- 方向二:文本向量化,尝试不同的文本向量化方法或模型
- 方向三:分类器,尝试不同的分类器算法
- 方向四:端到端,微调大模型实现端到端的预测
实验一:传统机器学习
- 文本向量化方法:
- TF-IDF 算法
- OpenAI 的
text-embedding-ada-002模型
- 分类算法选择 scikit-learn 库中的一系列机器学习分类器:
- LinearSVC
- BernoulliNB
- SGDClassifier
- AdaBoostClassifier
- RandomForestClassifier
- GradientBoostingClassifier
- DecisionTreeClassifier
- MLPClassifier
- 两两组合记录预测结果
| 排名 | 文本向量化方法 | 分类器算法 | 预测准确率 |
|---|---|---|---|
| 1 | text-embedding-ada-002 | SGDClassifier | 86.43% |
| 2 | text-embedding-ada-002 | LinearSVC | 85.67% |
| 3 | TF-IDF | RandomForestClassifier | 83.79% |
| 4 | TF-IDF | GradientBoostingClassifier | 83.33% |
| 5 | TF-IDF | SGDClassifier | 82.96% |
| 6 | TF-IDF | LinearSVC | 82.88% |
| 7 | text-embedding-ada-002 | MLPClassifier | 82.28% |
| 8 | TF-IDF | MLPClassifier | 81.98% |
| 9 | TF-IDF | AdaBoostClassifier | 81.00% |
| 10 | text-embedding-ada-002 | GradientBoostingClassifier | 80.24% |
| 11 | TF-IDF | DecisionTreeClassifier | 78.81% |
| 12 | text-embedding-ada-002 | RandomForestClassifier | 76.40% |
| 13 | text-embedding-ada-002 | BernoulliNB | 76.09% |
| 14 | TF-IDF | BernoulliNB | 75.94% |
| 15 | text-embedding-ada-002 | AdaBoostClassifier | 71.95% |
| 16 | text-embedding-ada-002 | DecisionTreeClassifier | 56.49% |
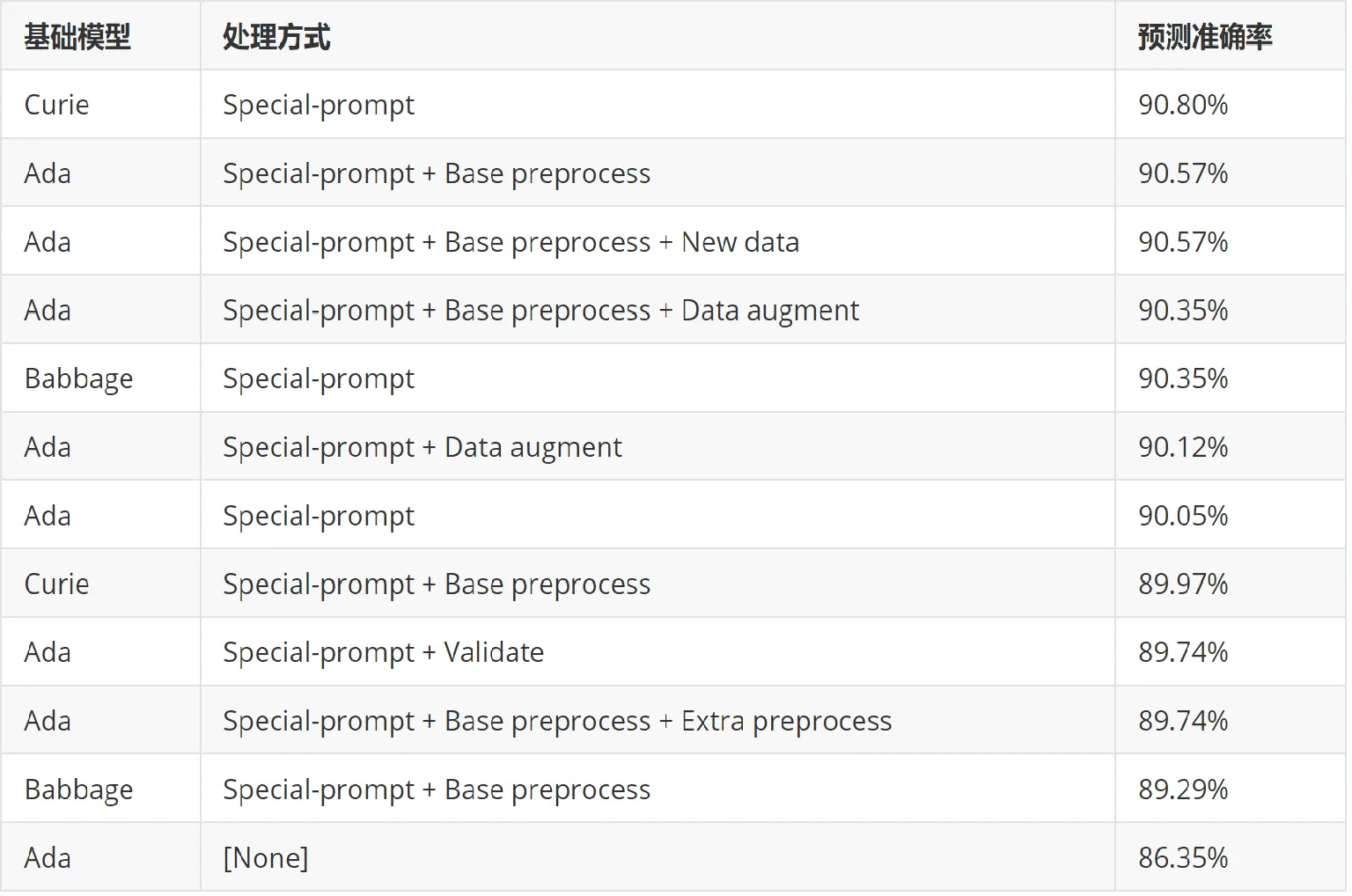
实验二:微调大模型
实验分析
嵌入模型和 TF-IDF 算法对比分析
TF-IDF 是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,算法简单高效、可解释性强,根据词频和逆文档频率,将目标文本转换为向量(长度不固定)
Embedding 通过预训练的模型直接将单词映射到向量空间,更能表现词的上下文结构,由词向量叠加得到目标文本对应的向量(长度固定)
选用的分类器中非神经网络的模型(如决策树、随机森林)无法理解向量空间的特征,与 Embedding 模型不匹配,因此预测的效果反而较差,不如使用相对简单的 TF-IDF 算法
新增数据集没有效果的原因分析
- 同样是软件工程文本,不同数据来源的文本风格也存在较大的差异
- 爬取到的数据中,情感标注结果为中性的文本项较多,数据分布不平均
对微调大模型的对照实验分析
参数量更大的模型对于提升预测准确率有一定的帮助
基于同义词替换的数据增强对于参数量相对较少的 Ada 模型有效,但对更大的模型反而会抑制泛化效果
对文本的预处理对于参数量相对较少的 Ada 模型有效,但对更大的模型反而会抑制泛化效果